Agentic Data Engineering Tutorial: How to Build Self-Healing Pipelines
This Agentic Data Engineering Tutorial shows how AI agents can keep your data pipelines healthy instead of waiting for failures and manual fixes. Agentic data engineering adds a reasoning layer on top of your existing tools so pipelines can detect issues, understand them, and respond with controlled actions.
The focus here is practical. You will see the core building blocks of an agentic stack and a concrete walk-through for a self-healing pipeline. The aim is to cut pipeline debt, reduce noisy on-call work, and keep business data flowing with far less manual intervention.
Table of Contents
- What Is Agentic Data Engineering?
- From Reactive Pipelines to Self-Healing Systems
- Three Pillars of an Agentic Data Engineering Stack
- Zero-ETL and Lakehouse as the Foundation
- Agentic Data Engineering Tutorial: Build a Self-Healing Pipeline
- Governance, Safety, and Human-in-the-Loop
- Agentic Data Engineering Tutorial: Burning Questions
- Official Docs and Deep-Dive Resources
- Related Lakehouse & Data Engineering Guides
What Is Agentic Data Engineering?
Agentic Data Engineering uses AI agents as a thin reasoning layer on top of your data platform. These agents read telemetry, logs, and contracts, then call tools such as SQL runners, orchestration APIs, or ticketing systems to keep pipelines running smoothly.
Unlike simple scripts or chatbots, agentic systems work in a loop. They observe pipeline behavior, decide on the next step, act through well-defined tools, and learn from outcomes. The orchestrator still handles scheduling and dependencies, while agents take on triage, diagnosis, and safe automation of repetitive recovery tasks.
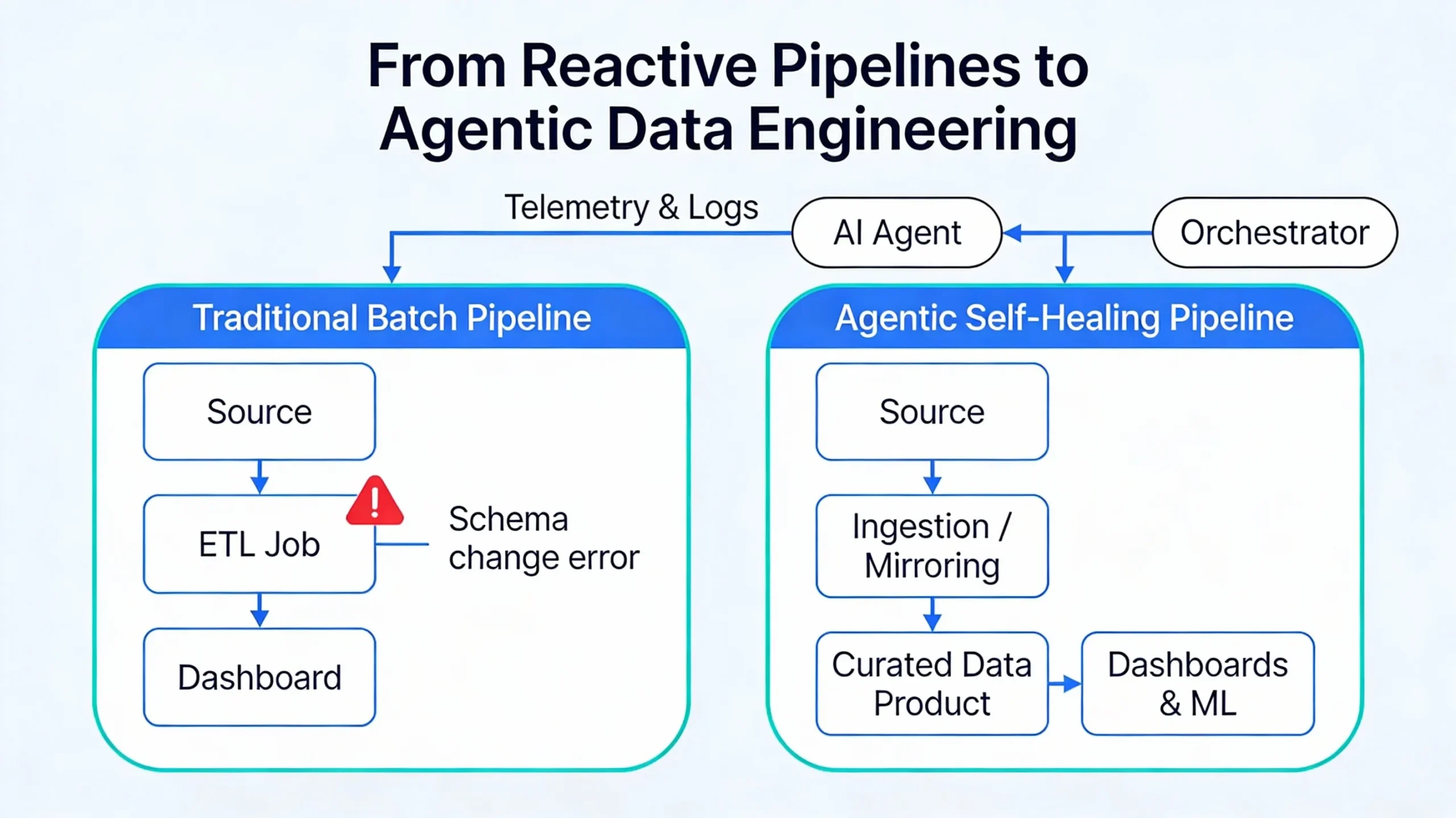
From Reactive Pipelines to Self-Healing Systems
Traditional batch pipelines react badly to change. A small schema tweak upstream, a missed file, or a short outage in a dependency often means failed jobs, broken dashboards, and a scramble to patch things before the next business review.
Self-healing pipelines aim for the opposite pattern. Observability systems watch freshness, volume, schema changes, and error rates. When something looks off, alerts and structured events give an agent the context it needs. The agent can then classify the issue, apply a safe recovery step, or propose a fix that a human can review.
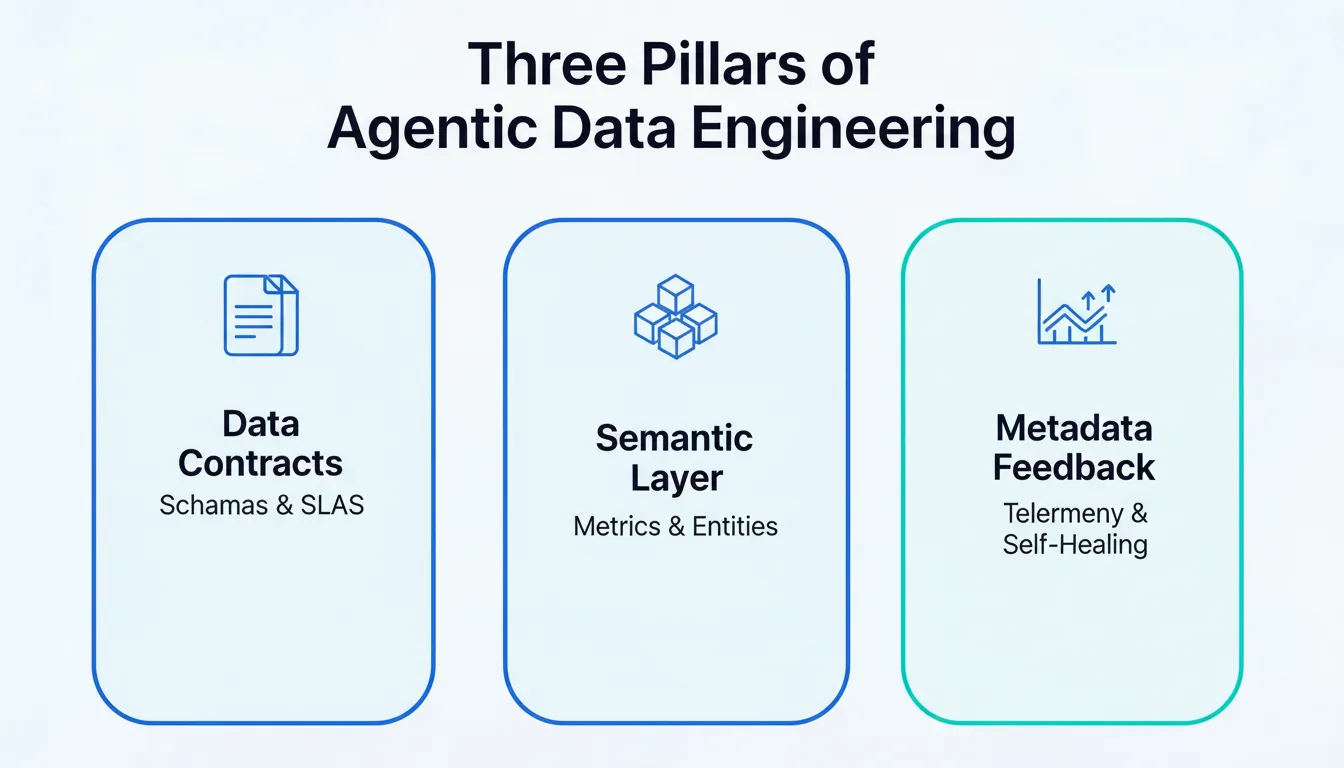
Three Pillars of an Agentic Data Engineering Stack
Agentic Data Engineering is more than plugging an LLM into a DAG. Reliable stacks rely on three main pillars: data contracts as guardrails, a semantic layer as the source of truth, and metadata feedback loops that enable self-healing behavior.
When these pillars are in place, agents work inside clear boundaries, rely on trusted definitions for metrics, and have the context required to make useful, safe decisions about broken pipelines.
Data Contracts and Typed Interfaces
Data contracts describe what producers promise and what consumers can trust. They define schemas, data types, required fields, and sometimes SLAs such as expected freshness or volume. Contracts can live as Pydantic models, JSON Schema, dbt schema YAML, or similar formats.
In an agentic stack, these contracts act as firm guardrails. Every tool the agent uses, from SQL generation to ingestion jobs, has typed inputs and outputs that must match the contract. When an agent suggests a change, validation checks the proposal. If the new shape violates the contract, the system blocks the change and instead surfaces a suggested contract update for review.
Semantic Layer and Metric Governance
The semantic layer defines business concepts and metrics in one consistent place. Systems like the dbt Semantic Layer and related tools describe entities, relationships, and metrics as configuration and expose them through APIs and governed SQL endpoints.
Agents benefit because they can request named metrics and entities rather than writing raw SQL against arbitrary tables. When a self-healing agent needs to ask whether yesterday’s revenue looks normal, it calls a metric service. Business logic stays in the semantic layer, and agent behavior stays aligned with the definitions analysts already use.
Metadata-Driven Feedback and Self-Healing
Robust self-healing depends on good metadata. Pipelines need structured records about job runs, failures, volume changes, schema events, and lineage. That metadata powers anomaly detection, failure classification, and targeted remediation strategies.
A practical feedback loop works like this: a job fails or an anomaly raises a flag, observability emits structured events, the agent reads those events, classifies what happened, and chooses a response. Simple responses such as retries with backoff or reruns after a transient network error can be fully automated. More complex scenarios, including schema changes and contract updates, become suggested pull requests or tickets rather than silent code changes.
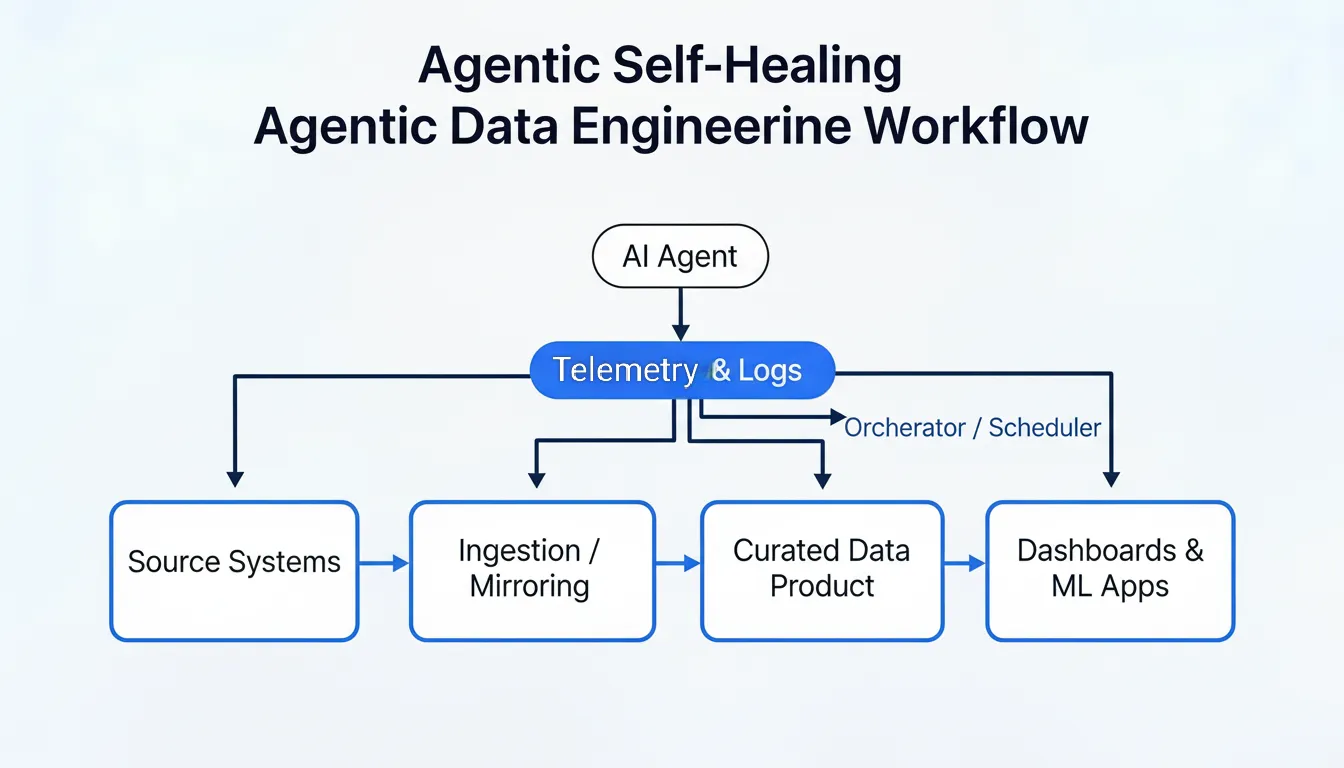
Zero-ETL and Lakehouse as the Foundation
Agentic pipelines work best when the base architecture is simple and consistent. Zero-ETL and mirroring features in modern platforms replicate data from operational systems directly into a lakehouse or warehouse with minimal custom ingestion logic.
Once mirrored data lands reliably, engineers and agents can focus on modeling, contracts, quality, and recovery logic instead of raw extraction. The resulting stack looks layered: source systems feed mirroring or streaming ingestion, curated layers and data products sit on top, the semantic layer defines metrics and entities, and agents monitor and act across the full path.
Agentic Data Engineering Tutorial: Build a Self-Healing Pipeline
The rest of this Agentic Data Engineering Tutorial walks through a simple but realistic example. The scenario is a daily Orders snapshot that feeds revenue dashboards. The aim is to detect schema drift and common failures, then let an agent respond with safe, repeatable actions.
You can adapt the pattern to Fabric, Databricks, Snowflake, BigQuery, or any other modern lakehouse. The exact tools may differ, yet the core steps stay the same: define a data product and contract, model it in your semantic layer, add telemetry, and wire an agent around your orchestrator.
Step 1: Define the Data Product and Contract
Begin by naming the data product and describing who uses it. For example, call it “Orders_Daily_Snapshot” for the Revenue Analytics team, serving questions such as “What were yesterday’s orders and gross revenue by region?” and “How does the last seven days compare to the previous week?”. This framing turns a table into a product with a clear audience.
Next, write down the contract for the curated table. Use a Pydantic model or a JSON Schema definition that lists fields like order_id, order_date, customer_id, currency, gross_amount, discount_amount, and order_status. Mirror the same contract in your dbt schema or warehouse DDL so both your agent and your transformations agree on structure and constraints.
Step 2: Implement the Semantic Model
With the contract in place, build a dbt model or equivalent that produces Orders_Daily_Snapshot from mirrored or raw data. Add tests for primary keys, not-null constraints on core fields, and any obvious domain rules, such as non-negative amounts.
Then define metrics in your semantic layer or metrics store. Metrics like orders_count_1d, revenue_7d, and average_order_value become named definitions rather than ad-hoc queries. Humans access them through BI tools or SQL. Agents call those same metrics via API or semantic SQL, which keeps everyone on a shared, governed definition of “revenue”.
Step 3: Add Observability and Metadata
Now instrument the pipeline with telemetry. Each run should record when it started, when it finished, how many rows it processed, whether tests passed, and what kind of errors occurred if something went wrong. Store these records in a telemetry table or send them into your observability system.
On top of these records, define simple rules and anomaly checks. For example, raise an alert when freshness exceeds a set threshold, when volume drops by more than a percentage compared to recent history, or when schema changes appear on upstream sources. These signals tell an agent when to wake up and start reasoning about a problem.
Step 4: Wire an Agent for Failure Triage and Recovery
Finally, connect an agent framework that can see telemetry, read contracts, and call tools. Give the agent tools that fetch recent logs, read contract definitions, trigger retries, open pull requests, and create tickets in your incident system. Each tool should have clear inputs and outputs so the agent can be validated and constrained.
Implement a basic self-healing policy. When the agent sees a transient network error or a short-lived infrastructure issue, it retries with backoff and logs the decision. When it sees a schema change that still fits the contract, it can propose a dbt or transformation patch as a pull request for an engineer to review. When the change breaks the contract, the agent raises a ticket and attaches a human-readable explanation, instead of silently pushing code into production.

Governance, Safety, and Human-in-the-Loop
Autonomous behavior can deliver huge value, but it also raises fair concerns. You do not want a misconfigured agent to rewrite core metrics or silently drop columns in a regulatory report. Clear safety rules turn agents into helpful assistants instead of unpredictable actors.
A simple policy is to classify actions by risk. Low-risk actions such as retries, idempotent reruns, and rerouting to a known fallback source can be fully automated and logged. Medium-risk actions like adding a non-breaking column or tuning a timeout should create pull requests that humans review. High-risk actions, including contract changes, breaking schema updates, or large SQL rewrites, always require explicit human approval and sometimes an architectural review.
Agentic Data Engineering Tutorial: Burning Questions
Is Agentic Data Engineering just AI agents applied to pipelines?
Agentic Data Engineering uses AI agents inside the rules and boundaries of a data platform. Generic agents may not respect contracts, access controls, or semantic definitions. Agentic patterns explicitly tie agents to contracts, metrics, telemetry, and governance so they behave like reliable team members instead of experiments running in production.
Do I need a semantic layer before I build agents?
Strictly speaking, you can start without a semantic layer, but the experience will be weaker. A semantic layer gives clear names and definitions to metrics and entities. When agents rely on that layer instead of raw tables, you get fewer surprises, better reuse, and easier debugging if something goes wrong.
How do data contracts, data quality checks, and agents work together?
Data contracts define structure and expectations at the boundaries. Data quality checks verify that real data meets those expectations. Agents sit on top of both, using contract definitions and test results as inputs when they decide whether to retry, quarantine, or propose changes to code or configuration.
Where should I start if my stack is mostly batch Airflow and dbt?
A good first step is to choose one critical pipeline and harden it. Add a clear contract for inputs and outputs, add richer telemetry, and create a semantic model for the key metrics. Once that is in place, introduce a small agent that focuses only on failure triage and simple retries. Expanding from one pipeline to many becomes easier after you have one working pattern.
When is it safe to let agents auto-fix pipelines?
Safe automation tends to involve actions that are reversible, well understood, and easy to monitor. Retrying after transient issues, reprocessing a known batch, or switching to a stable fallback source fits this description. Schema updates, contract changes, and complex query rewrites almost always belong in the category of “propose a fix, let a human approve”.
Will Agentic Data Engineering replace human data engineers?
Agents are effective at repetitive triage and pattern-based fixes. Humans excel at understanding business context, designing good contracts, and shaping long-term architecture. In practice, agentic systems shift the role of data engineers toward platform design, governance, and higher-level reliability work rather than day-to-day fire drills.
How does Agentic Data Engineering relate to observability tools?
Observability tools remain the foundation because they collect metrics, logs, and traces. Agentic Data Engineering builds on that foundation. Agents consume the signals produced by observability and then decide which tool to call or which action to take, so you get more value from the data you already monitor.
What skills should data engineers develop for an agentic future?
Engineers who understand contracts, semantic modeling, observability, and agent frameworks will have an edge. Strong skills in Python, SQL, orchestration, and designing safe tool interfaces for agents will be more important than writing one-off glue code. Communication and governance skills also become more valuable as automation spreads.
Can I apply Agentic Data Engineering to streaming workloads?
Agentic ideas extend naturally to streaming systems. Agents can watch lag, throughput, and error rates, then trigger actions such as scaling, rerouting, or switching to a different consumer group. The same principles apply: contracts for event schemas, a semantic view of key metrics, rich telemetry, and a clear separation between safe automatic actions and higher-risk changes.
How do I explain Agentic Data Engineering to business stakeholders?
One simple explanation is that you are teaching the data platform to handle common incidents on its own. Instead of dashboards failing silently or teams waiting hours for fixes, the system detects problems early, applies safe recovery steps, and flags only the harder cases for human review. That means fewer outages, faster incident response, and more reliable decision-making.



