Apache Iceberg vs Delta Lake – The Ultimate Comparison for Lakehouse Architecture
The Apache Iceberg vs Delta Lake debate sits at the heart of modern lakehouse architecture. Traditional data lakes were cheap and flexible but lacked ACID guarantees and strong governance. Classic data warehouses were reliable and performant but locked you into expensive, rigid storage and compute.
Lakehouse table formats solve this by bringing ACID transactions to object storage. Apache Iceberg and Delta Lake both do this, but they use different approaches to metadata, concurrency, and ecosystem integration. This guide breaks down those differences so you can choose the right table format for your 2026 lakehouse.
💡 Thinking about starting a small side income online?
Many creators start with simple tools and workflows — no investment required.
See how creators do it → CreatorOpsMatrix.comLakehouse Table Formats in the Data Architecture Stack
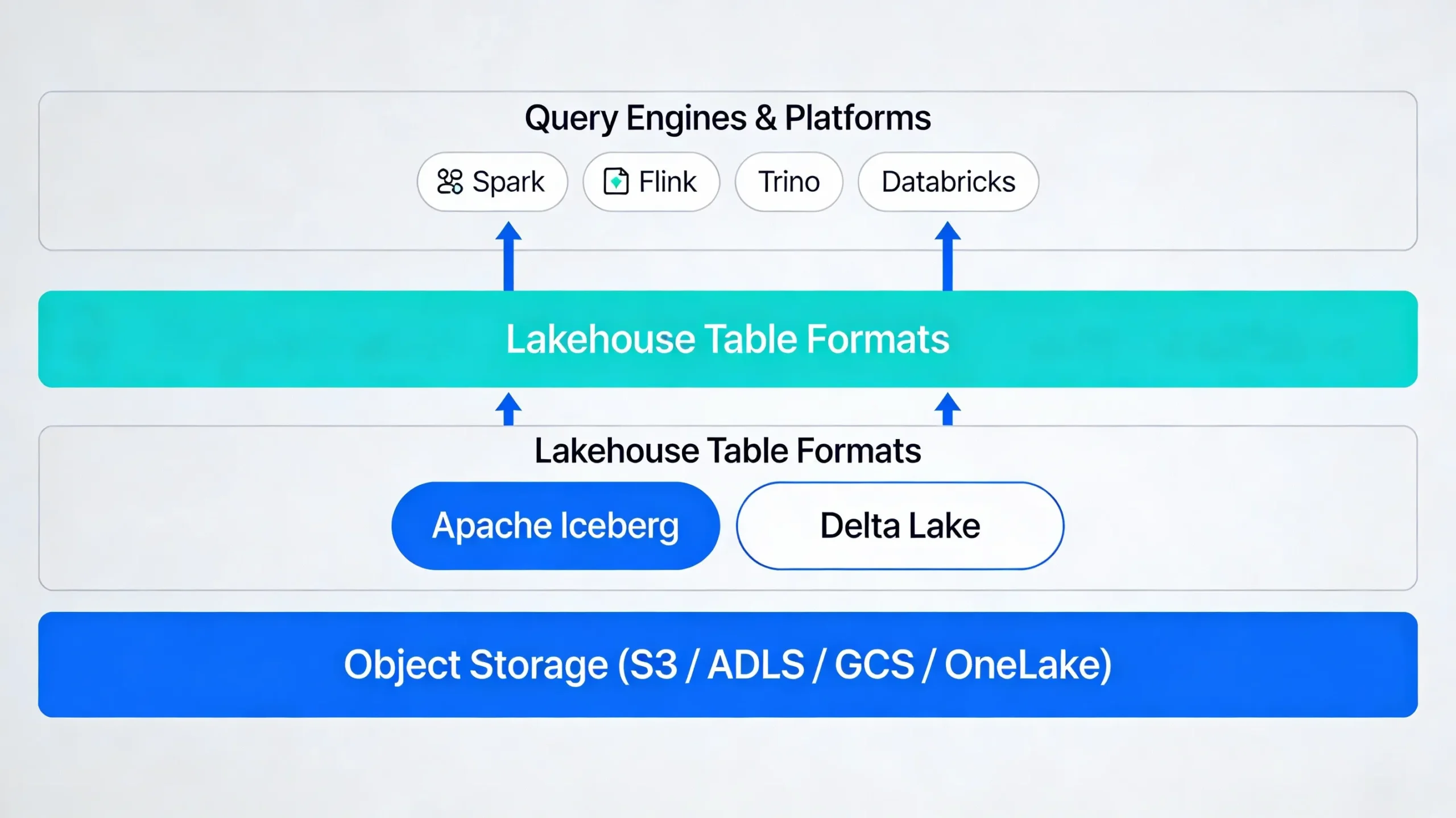
Modern data platforms often follow a layered design: raw data lands in object storage, a lakehouse table format provides ACID and governance, and engines like Spark, Flink, Trino, or Snowflake query that data. Apache Iceberg and Delta Lake both sit in this table format layer and define how tables evolve and how queries see consistent snapshots.
At a high level, this means you are choosing more than a file layout. You are choosing how metadata is stored, how transactions work, and how easy it is to use the same data across multiple compute engines and clouds.
What Is Apache Iceberg?
Apache Iceberg is an open table format designed to bring reliable, high-performance analytics to cloud object storage. It treats a table as a set of metadata files that describe snapshots, partitions, and data files, rather than relying on directory listings alone.
Iceberg supports Parquet, ORC, and Avro file formats and is deeply integrated with engines like Spark, Flink, Trino, Presto, and modern cloud warehouses. Its design focuses on very large tables, safe schema evolution, and a vendor-neutral governance model.
What Is Delta Lake?
Delta Lake is an open source table format that adds ACID transactions and schema enforcement on top of Parquet data in cloud storage. It organizes table changes in a transaction log called _delta_log, with JSON commit files and Parquet checkpoints to speed up planning.
Delta Lake is closely associated with Databricks and the Spark ecosystem. It offers strong support for streaming, batch workloads, and machine learning pipelines, especially when used with Databricks-managed runtimes and features like Delta Live Tables.
Apache Iceberg vs Delta Lake: Core Architectural Differences
The biggest difference between Apache Iceberg and Delta Lake is how they manage table metadata and transactions. Both deliver ACID guarantees on object storage, but their internal designs lead to different trade-offs for scale, interoperability, and operations.
Iceberg uses a metadata tree of snapshots and manifests, while Delta Lake uses an append-only transaction log with checkpoints. Understanding this contrast is key to designing a lakehouse that will scale and remain flexible over time.
Metadata Management and Table Snapshots
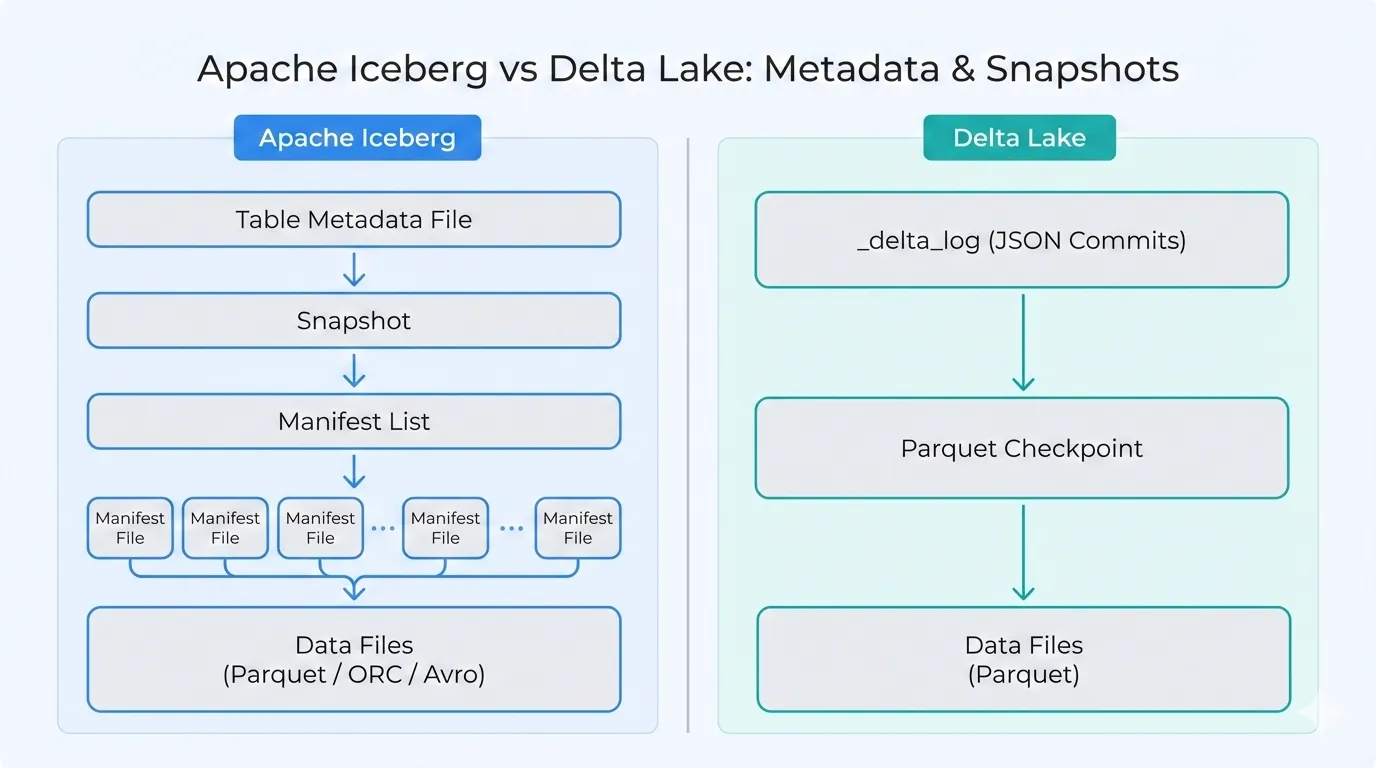
Apache Iceberg represents a table as a series of snapshots. Each snapshot points to one or more manifest lists, which in turn point to manifest files that reference the actual data files and partition information. A table metadata file tracks the current snapshot and schema. This approach is optimized for very large tables and efficient partition pruning.
Delta Lake records every change in a _delta_log directory. Each commit is stored as a JSON file, and periodic Parquet checkpoints summarize the state so that engines do not need to replay the entire log. This model works very well for frequent updates and streaming workloads, especially in Spark-centric environments.
ACID Transactions and Concurrency Control
Both formats use optimistic concurrency control, but they integrate with engines differently. Iceberg relies on catalogs to coordinate commits, allowing multiple engines such as Spark, Flink, and Trino to update the same table with consistent semantics.
Delta Lake implements concurrency around the transaction log. In practice, this works best in Databricks and Spark runtimes that understand the log and conflict detection rules. Other engines can read Delta tables, but write semantics are most mature in the Spark ecosystem.
Schema Evolution, Time Travel, and Governance
Schema evolution and time travel are central to any lakehouse architecture. As tables grow and business needs change, you must be able to add columns, change types safely, and query historical versions without corrupting downstream consumers.
Apache Iceberg and Delta Lake both support schema evolution and time travel, but they differ in how much flexibility they offer and how they enforce compatibility over time.
Schema Evolution in Apache Iceberg vs Delta Lake
Apache Iceberg supports rich, type-safe schema evolution. It tracks columns by ID rather than by position, which makes renames and reordering safer. Iceberg can handle a wide range of schema changes while preserving existing data and queries.
Delta Lake also supports schema evolution, including adding columns and certain type changes. However, its model is generally more restrictive than Iceberg’s, and advanced changes often require more manual planning and testing.
Time Travel and Data Versioning
With Iceberg, time travel is implemented through snapshots. Each snapshot records which data files are active at a given point in time, and engines can query a table as of a snapshot ID or timestamp. This makes it straightforward to debug issues or reproduce historical reports.
Delta Lake exposes time travel through its transaction log. You can query a table by version number or timestamp, which maps to a specific point in the log. This is particularly useful for auditing, rollback, and reproducible analytics in Spark-based workflows.
Performance and Scalability: Which Is Faster?
Performance in a lakehouse depends on more than just the table format. Engine optimization, file layout, partitioning, and compaction all play major roles. Even so, Apache Iceberg and Delta Lake do make different performance trade-offs through their metadata and layout designs.
Instead of asking which format is universally faster, it is more helpful to compare how each behaves under typical analytics, streaming, and CDC workloads.
Query Planning and Metadata Scale
Apache Iceberg uses manifests and partition statistics to prune data files before a query hits storage. This design shines for very large tables with many partitions and billions of files, where efficient planning can dramatically reduce scan costs.
Delta Lake relies on its transaction log and checkpoints, which must be maintained through optimize and vacuum operations. When tuned well, this setup offers excellent performance, but it requires deliberate housekeeping to keep the log and small files under control.
Read and Write Patterns
Both formats support batch and streaming writes, as well as updates and deletes. Iceberg often emphasizes efficient planning and flexible layout, making it attractive for large batch analytics and mixed-engine workloads.
Delta Lake is highly optimized for Spark-based streaming, upserts, and real-time dashboards, especially when combined with Databricks features like Delta Engine and auto compaction. For many teams, this leads to very strong performance with relatively simple configuration.
Ecosystem and Vendor Lock-In: Open vs Platform-Centric
Choosing a table format is also a strategic decision about your ecosystem. Apache Iceberg and Delta Lake differ in how open their specifications are, how many engines they support, and how tightly they are coupled to specific vendors.
In 2026 and beyond, these ecosystem choices determine how easy it will be to add new engines, change cloud providers, or adopt additional managed services without rewriting all your tables.
Engine and Platform Support
Apache Iceberg is designed as a vendor-neutral, Apache-governed standard. It is supported by Spark, Flink, Trino, Presto, and a growing list of cloud warehouses and lakehouse engines. This multi-engine support makes it a strong choice for organizations with diverse tooling.
Delta Lake offers the most mature experience in Databricks and Spark runtimes. Other engines can read Delta tables, but full-featured write support and advanced optimizations are typically strongest in the Databricks ecosystem.
Open Governance and Lock-In Considerations
Iceberg’s specification and governance model make it easier to adopt across clouds and vendors while keeping the table format itself open. This reduces long-term lock-in and allows teams to evolve their compute stack independently from their storage layer.
Delta Lake is open source at its core but remains closely associated with Databricks-managed services and optimizations. For Databricks-centric teams, this tight coupling is a feature, not a bug, because it delivers a highly integrated experience. For multi-cloud, multi-engine strategies, it may feel more constraining.
Apache Iceberg vs Delta Lake: Real-World Use Cases
Beyond architecture, the most practical way to compare Apache Iceberg vs Delta Lake is to look at common use cases. Different workloads emphasize different strengths, from multi-engine batch analytics to near real-time dashboards and ML feature stores.
This section outlines where each format tends to fit best, assuming you have the option to choose.
When Apache Iceberg Is Usually the Better Fit
- You run a multi-engine analytics platform with Spark, Flink, Trino, or Presto accessing the same data.
- You have very large tables and need efficient planning, flexible partitioning, and robust schema evolution.
- You want to minimize vendor lock-in and keep the table format open and portable across clouds and platforms.
When Delta Lake Is Usually the Better Fit
- Your platform is built primarily around Databricks and Spark for batch, streaming, and machine learning.
- You want tight integration with managed features like Delta Live Tables, notebooks, and built-in performance tuning.
- You prioritize fast streaming ingestion, upserts, and real-time dashboards within a Spark-centric stack.
How to Choose Apache Iceberg vs Delta Lake in 2026
There is no single winner for every team. Instead, the right choice depends on your engines, your cloud strategy, and your governance requirements. A simple decision framework can help you narrow down the best table format for your lakehouse.
Start by evaluating your existing tools and constraints, then apply a few clear rules of thumb rather than chasing benchmarks in isolation.
Key Decision Factors
- Current compute stack: Databricks-first vs multi-engine (Spark, Flink, Trino, Snowflake, Fabric, and others).
- Cloud and vendor strategy: Single cloud vs multi-cloud or hybrid deployments.
- Data governance: Compliance, audit needs, and how strictly you manage schema changes.
- Performance profile: Heavy streaming and upserts vs large batch analytics and interactive BI.
Simple Rules of Thumb
Choose Apache Iceberg if your priority is an open, vendor-neutral table format that works across many engines and clouds. It is especially compelling for large-scale batch analytics, complex schema evolution, and data platforms built around multiple query engines.
Choose Delta Lake if your priority is a deeply integrated, Spark-centric experience with strong support for streaming, ML, and managed Databricks features. It is a natural choice when your data platform and team are already tightly aligned to the Databricks ecosystem.
Apache Iceberg vs Delta Lake: Burning Questions Answered
Is Apache Iceberg better than Delta Lake for multi-cloud lakehouses?
Apache Iceberg is generally a better fit for multi-cloud and multi-engine lakehouses because its specification and governance model are vendor-neutral. It is designed to work consistently across Spark, Flink, Trino, and other engines, which makes it easier to move or add compute platforms over time.
Which is faster: Delta Lake or Apache Iceberg?
Neither format is always faster. Delta Lake often shows strong performance in Spark and Databricks environments, especially for streaming, upserts, and workloads tuned with Delta-specific features. Apache Iceberg often shines for very large analytic tables and mixed-engine workloads when you take full advantage of its partitioning and metadata pruning.
How do schema evolution and time travel differ between Iceberg and Delta Lake?
Iceberg emphasizes robust, type-safe schema evolution with column IDs, which makes advanced changes like renames and reordering safer. Delta Lake supports schema evolution and time travel through its transaction log, but it tends to be more restrictive for certain changes and relies heavily on Spark semantics.
Which is better for Databricks, and which for Trino or Starburst?
For Databricks, Delta Lake is the natural choice because it integrates deeply with the platform, runtime, and tooling. For Trino, Starburst, and other multi-engine or query federation environments, Apache Iceberg is usually the preferred option thanks to its open spec and broad engine support.
Apache Iceberg vs Delta Lake: Burning Questions Answered
Is Apache Iceberg better than Delta Lake for multi-cloud lakehouses?
Apache Iceberg is usually a better fit for multi-cloud lakehouses because it is designed as an open, vendor-neutral table format with broad engine support. Delta Lake can also be used across clouds, but its most mature and optimized experience remains in Databricks-centric environments.
Which is faster: Delta Lake or Apache Iceberg for analytics?
Performance depends on your engine, workload, and tuning. Delta Lake often excels for Spark and Databricks workloads, especially streaming and upserts tuned with Delta-specific features. Apache Iceberg often performs best for very large analytic tables, mixed-engine platforms, and well-designed partitioning and metadata pruning.
How do schema evolution capabilities compare between Iceberg and Delta Lake?
Iceberg emphasizes robust, type-safe schema evolution with column IDs, which makes renames and reordering safer for long-lived tables. Delta Lake supports schema evolution as well, but it tends to be more restrictive for certain changes and is closely tied to Spark semantics.
How does time travel work in Apache Iceberg vs Delta Lake?
Iceberg implements time travel through snapshots that record which data files are active at a given point in time. Delta Lake implements time travel through its transaction log, allowing queries by version or timestamp. Both enable reproducible analytics and easier debugging, but they rely on different internal mechanisms.
Which table format is better for streaming workloads and CDC pipelines?
Delta Lake has strong support for streaming and CDC-style pipelines in Spark and Databricks, making it a popular choice for near real-time dashboards and event-driven pipelines. Apache Iceberg also supports streaming and CDC in engines like Flink and Spark, and is gaining traction as streaming integrations mature.
Which format should I use with Databricks, Trino, Starburst, or Snowflake?
For Databricks, Delta Lake is the natural default because it integrates deeply with the runtime and managed services. For Trino, Starburst, Flink, Dremio, and Snowflake-centric platforms, Apache Iceberg is often preferred due to its open specification and wide engine support.
Is Apache Iceberg more future-proof than Delta Lake for open lakehouse architectures?
Iceberg’s open specification and governance make it attractive as a long-term, engine-agnostic choice for open lakehouse architectures. Delta Lake is also open source and continues to expand its footprint, but its deepest optimizations are tightly coupled to Databricks, which some teams see as a form of platform lock-in.
Can I migrate from Delta Lake to Apache Iceberg or vice versa without rewriting everything?
Migrations between formats are possible using read-and-rewrite patterns or specialized tools, but they are not free. You must align schemas, partitioning, and retention rules, and you may need to plan downtime or dual-write periods for critical tables.
Does the choice of table format still matter if my platform supports both Iceberg and Delta Lake?
The choice still matters because it affects how easily you can bring in new engines, share tables with partners, and evolve your platform over time. Even when a platform supports both formats, you should align your choice with your long-term ecosystem and governance strategy.
How do Apache Iceberg and Delta Lake compare to Apache Hudi?
Apache Hudi is another lakehouse table format with its own strengths in incremental processing and upserts. If you are primarily comparing Iceberg vs Delta Lake, Hudi enters the discussion when you need write-optimized pipelines and incremental ingestion patterns in specific ecosystems.
Is it possible that the table format war will not matter in a few years?
As more engines add support for multiple formats and migration tools improve, the table format war may feel less critical over time. Even so, your choice today still influences how easily you can adopt new engines, avoid lock-in, and manage schema and governance at scale.



