Fabric Lakehouse vs. Data Warehouse Best Practices: Which Architecture Is Right?
The Fabric Lakehouse vs Data Warehouse best practices debate is not about choosing a winner. In Microsoft Fabric, both the Lakehouse and the Warehouse sit on top of the same storage layer, OneLake. They also use Delta as the underlying table format. The real question is when you should lean on the Lakehouse, when you should use the Data Warehouse, and when you should combine both for a lake-centric warehouse approach.
This guide explains what each Fabric artifact is, why you would choose one over the other, and how to implement Fabric Lakehouse vs Data Warehouse best practices around architecture, governance, ingestion, and tooling. It stays aligned with Microsoft Fabric decision guides but adds practical examples for BI, analytics engineering, and data science teams.
What Is OneLake and Why Does It Change the Lakehouse vs Warehouse Debate?
OneLake is the unified, multi-tenant data lake for Microsoft Fabric. It behaves like “OneDrive for data”, so all Fabric items, including Lakehouses and Warehouses, store their data in OneLake in open formats. Instead of choosing separate storage engines, you are choosing different compute and modeling experiences over the same lake.
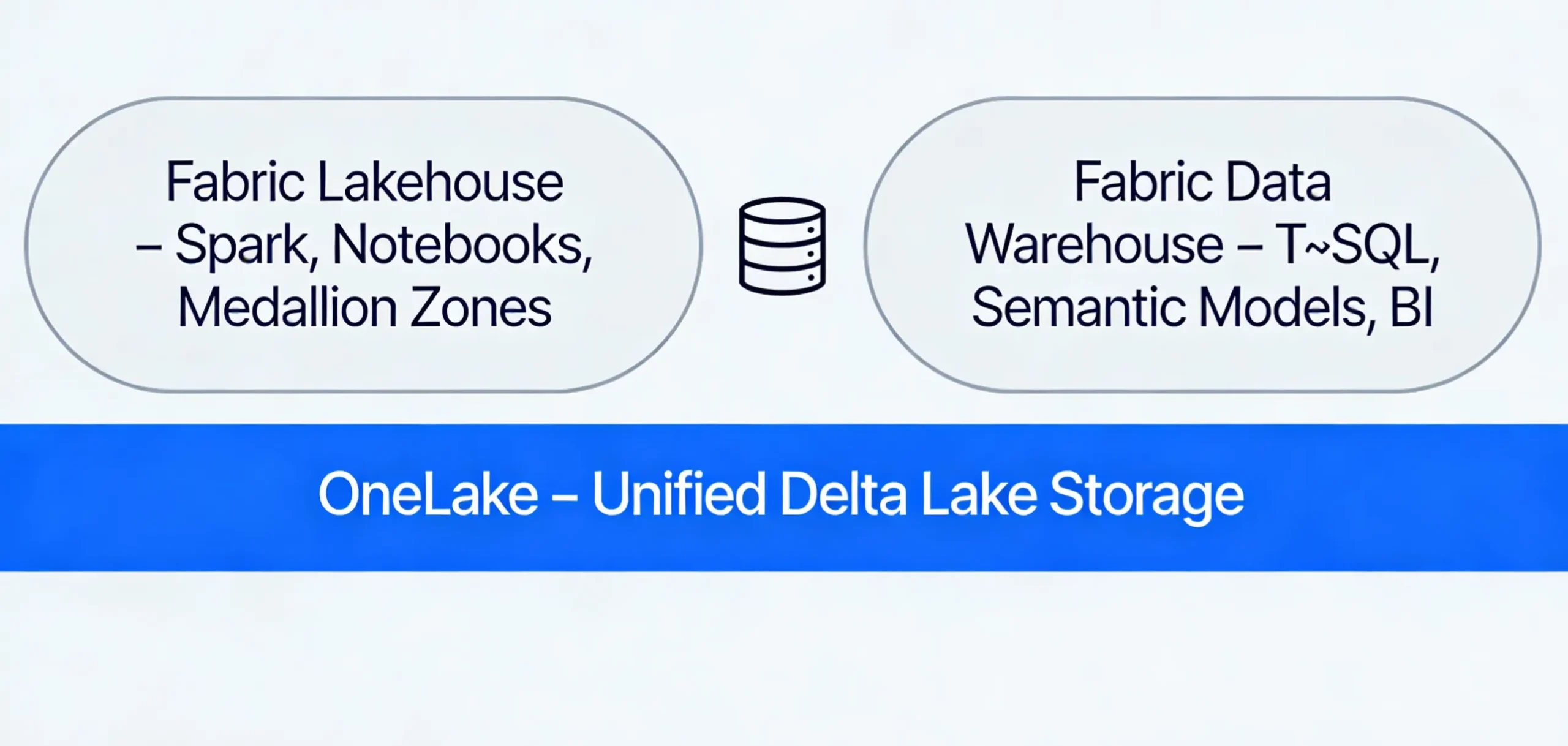
Both Fabric Lakehouse and Fabric Data Warehouse use Delta tables in OneLake for storage. However, they differ in how you access, model, and govern that data. Lakehouse is optimized for medallion-style data engineering and data science. Warehouse is optimized for SQL, semantic models, and BI-ready star schemas.
What Is a Fabric Lakehouse?
A Fabric Lakehouse is a lakehouse artifact that stores files and Delta tables in OneLake. It has built-in support for Spark, SQL analytics, and Power BI. Microsoft recommends it as the main way to implement medallion lakehouse architecture with bronze, silver, and gold layers.
Lakehouse is ideal when you work with large volumes of raw, semi-structured, or unstructured data. It also fits when you need flexible schema-on-read or when you combine Python, Scala, SQL, and notebooks. As a result, Lakehouse shines for ETL and ELT pipelines, data science experiments, and machine learning workloads that need full control over transformations and compute.
What Is a Fabric Data Warehouse?
A Fabric Data Warehouse is a lake-centric warehouse engine that stores data in Delta tables in OneLake. It provides a SQL-first experience with T-SQL, a Warehouse editor, and deep integration with Power BI. Direct Lake access from semantic models is a core feature.
Fabric Data Warehouse is ideal when you need governed, curated data for reporting and analytics. It supports star schemas, dimensional modeling, row-level security, and consistent performance for BI workloads. Teams coming from SQL Server, Azure Synapse, or traditional data warehouse platforms usually feel at home here.
How Does Medallion Architecture Work in Fabric Lakehouse?
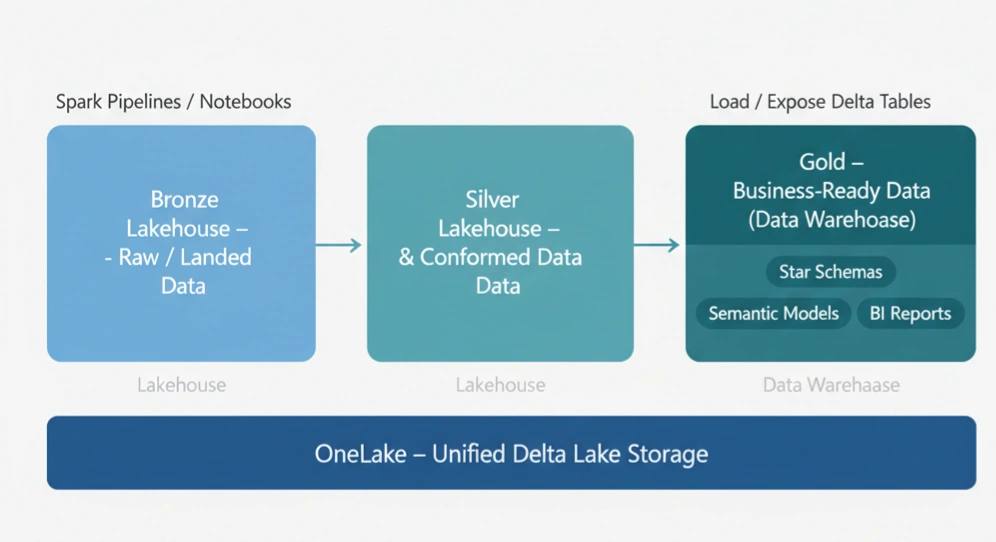
Medallion architecture is Fabric’s recommended design pattern for organizing data in a Lakehouse. You structure data into three zones: bronze, silver, and gold. Bronze holds raw or landed data. Silver stores cleaned and conformed data. Gold contains business-ready, aggregated data for consumption.
In Fabric, each zone can be implemented as one or more Lakehouses in OneLake, often in separate workspaces for better governance. Bronze Lakehouses can point to external sources using shortcuts. Silver and gold Lakehouses typically store Delta tables with higher quality and stricter contracts. You can also use materialized lake views to automate transformations between these layers and simplify medallion pipelines.

Lakehouse and Warehouse Together: Gold Zone Best Practice
Fabric documentation describes a “better together” pattern. In this design, bronze and silver zones are implemented as Lakehouses for flexible ingestion and transformation. The gold zone is implemented as a Data Warehouse for curated, SQL-first consumption.
This pattern lets data engineers use Lakehouse and Spark for heavy transformations. At the same time, BI teams rely on Warehouse for T-SQL, semantic models, and Direct Lake Power BI reports. All layers still live in OneLake and share Delta tables, so you do not need to duplicate data into separate storage systems.
How Do Governance and Security Differ Between Lakehouse and Warehouse?
Because both Lakehouse and Warehouse use OneLake and Delta, governance is consistent at the storage level. However, each artifact exposes different access and modeling surfaces. Lakehouse governance focuses on workspace and item permissions, filesystem-level access, table ACLs, and SQL analytics endpoint permissions. This model suits technical teams managing medallion zones and data products across workspaces.
Warehouse governance extends familiar SQL security concepts. You work with schemas, roles, dynamic data masking, row-level security, and granular permissions on tables and views. This model provides a clear, centralized approach for BI and reporting teams, especially when combined with semantic models and Power BI.
How Do SQL, Spark, and Notebooks Fit into Lakehouse vs Warehouse?
Fabric’s main strength is that it unifies SQL, Spark, Python, R, and Power BI on OneLake. Lakehouse is the natural home for Spark notebooks, data engineering pipelines, and machine learning experiments. It also exposes a SQL analytics endpoint, but its key advantage is flexibility for code-first transformations.
Warehouse is the natural home for SQL-based modeling and BI. It offers a rich T-SQL surface, familiar tools for database developers, and tight integration with Power BI semantic models. Many teams adopt a hybrid approach: data engineers build Lakehouse pipelines with Spark, while BI developers work primarily in the Warehouse and Power BI layers.
Ingestion Best Practices: Pipelines, Dataflows, Eventstreams, and Spark
Fabric provides several ingestion options: Data Factory pipelines, Dataflows, Eventstreams, and Spark. Pipelines are ideal for batch ingestion from databases and SaaS sources into Lakehouse or Warehouse tables. Dataflows are useful for low-code data preparation, especially for business users.
Eventstreams offer a managed way to capture and route real-time data into Lakehouse or Real-Time Analytics. For advanced ETL and ELT, Spark notebooks or Spark jobs often land data in bronze Lakehouses and then transform it into silver and gold layers. A practical best practice is to use Pipelines and Eventstreams to land data into Lakehouse zones, and then use Spark or Dataflows to move data through medallion layers.

Fabric Lakehouse vs Data Warehouse Best Practices for BI and Data Science
For BI and reporting workloads that depend on star schemas, conformed dimensions, and predictable performance, a Fabric Data Warehouse on top of OneLake is often the best fit. It integrates tightly with Power BI and makes it easy to define measures and semantic models over curated tables.
For data engineering and data science workloads that handle raw logs, semi-structured data, and large-scale transformations, a Fabric Lakehouse is usually the better starting point. It supports Spark, notebooks, and complex ETL patterns with medallion zoning. In practice, many teams follow Fabric Lakehouse vs Data Warehouse best practices by using Lakehouse for ingestion and transformation and Warehouse for curated consumption.
How Do Cost and Performance Compare Between Fabric Lakehouse and Warehouse?
Both Lakehouse and Warehouse share OneLake and Fabric capacity. Cost and performance therefore depend more on query patterns and data models than on completely different infrastructure stacks. Warehouse is tuned for high-concurrency SQL workloads and BI patterns. It can deliver predictable performance for dashboards and reports when schemas are well designed.
Lakehouse performance depends more on Spark job design, partitioning, file layout, and medallion pipelines. It offers flexibility and can be cost-effective for large-scale transformations and machine learning. However, it may require more engineering effort to tune. A balanced approach lets Lakehouse handle heavy transformations off-peak and lets Warehouse serve interactive queries and BI during business hours.
Fabric Lakehouse vs Data Warehouse: Burning Questions Answered
Is Fabric Lakehouse replacing the traditional Data Warehouse?
No. In Fabric, the Lakehouse is not a replacement for the Warehouse. Both run on OneLake and Delta. The platform is designed so that you can use them together. Lakehouse excels at raw and transformed zones for analytics engineering and data science. Data Warehouse excels at curated, governed tables and BI workloads.
When should I choose Fabric Lakehouse instead of Fabric Data Warehouse?
Choose a Fabric Lakehouse when you ingest diverse data types or need flexible schema-on-read. It is also a good choice when you run large data engineering or ML pipelines in Spark or Python. Lakehouse is well suited for bronze and silver medallion zones where raw and cleaned data evolve quickly.
When should I choose Fabric Data Warehouse instead of Lakehouse?
Choose Fabric Data Warehouse when your primary goal is to serve consistent, governed tables to BI and reporting users. Warehouse is ideal for gold-zone data products, star schemas, and semantic models. It offers familiar T-SQL, strong security, and predictable performance for interactive queries and dashboards.
Can I combine Fabric Lakehouse and Data Warehouse in one architecture?
Yes. A common best practice is to use a Lakehouse for bronze and silver zones and a Data Warehouse as the gold zone. Raw data lands in bronze Lakehouses. It is then cleaned and conformed in silver Lakehouses. Finally, curated data is loaded or exposed into a Warehouse for consumption. This “better together” pattern leverages both engines while keeping data in OneLake.
How does OneLake affect my Lakehouse vs Warehouse decision?
OneLake means you are no longer choosing between separate storage systems. Both Lakehouse and Warehouse store data in Delta tables on the same lake. The decision is therefore about how you access and govern that data. Lakehouse gives you Spark and notebooks. Warehouse gives you T-SQL and BI-oriented modeling.
How do medallion zones map to Lakehouse and Warehouse in Fabric?
Most teams implement medallion zones using Lakehouses. Bronze and silver zones live in Lakehouses where data is landed, cleansed, and conformed. For the gold zone, you can either expose a Lakehouse SQL analytics endpoint or create a Data Warehouse over the gold data. Many teams choose a Warehouse at this layer to take advantage of SQL modeling and BI features.
What are best practices for ingestion into Lakehouse vs Warehouse?
A practical pattern is to ingest raw data into a bronze Lakehouse using pipelines, Dataflows, or Eventstreams. Spark or Dataflows then move data into silver and gold zones. When you use a Warehouse, you can load curated silver or gold data into Warehouse tables. You can also let the Warehouse read from Delta tables in OneLake that were prepared by Lakehouse pipelines.
How do I choose tools: SQL vs Spark vs notebooks in Fabric?
Use Spark and notebooks in Lakehouse when you need flexible code-first transformations, machine learning, or advanced analytics. Use SQL in Warehouse when you need stable, governed models and BI-ready tables. In many projects, data engineers work in Lakehouse with Spark. BI developers and analysts work in Warehouse with T-SQL and Power BI.
Should every medallion tier be its own Lakehouse in Fabric?
Some designs use a separate Lakehouse for each medallion tier. Others keep multiple tiers in one Lakehouse and rely on schemas and naming conventions. Separate Lakehouses improve security and lineage clarity but increase item count. A shared Lakehouse reduces management overhead but requires strict governance and documentation.
When should I use Real-Time Analytics or Eventstreams instead of Lakehouse or Warehouse?
Use Eventstreams and Real-Time Analytics when you need near real-time ingestion and analysis of streaming data such as telemetry or clickstreams. Eventstreams can land events in a Lakehouse for historical analysis. Real-Time Analytics can serve operational dashboards. Lakehouse and Warehouse then handle longer-term modeling and BI.
Can I start with Lakehouse and add a Warehouse later in Fabric?
Yes. Many teams start with a Lakehouse for ingestion and transformation because it is flexible and fast to set up. Once gold-zone tables and business definitions stabilize, they add a Fabric Data Warehouse on top of the same OneLake data or load curated data into Warehouse tables. This staged approach allows you to deliver value early and add a warehouse layer when it is clearly justified.
What is the best long-term strategy for Fabric Lakehouse vs Data Warehouse?
Over time, most organizations benefit from a hybrid strategy. Lakehouse serves as the backbone for medallion pipelines and advanced analytics. Warehouse provides curated BI and semantic models. When you design with OneLake at the center and treat Lakehouse and Warehouse as complementary engines, you keep options open as workloads and teams evolve.



