Microsoft Web IQ: The Grounding API Built for AI Agents
Standard search APIs return ranked document links built for human browsers. Microsoft Web IQ returns something different — passage-level evidence objects that AI agents can consume directly, at 164ms P95 latency across five global data centers. This guide covers what Web IQ is, how its architecture works, and what it means for developers building agentic AI systems.
Microsoft Web IQ is a suite of AI-native grounding APIs launched at Build 2026 that connects AI agents to live web intelligence — web pages, news, images, and videos — from Bing’s re-architected global index. It returns passage-level evidence objects rather than full document links, operating at 164ms P95 latency — nearly 2.5× faster than the next-best alternative. It already powers grounding inside Microsoft Copilot and ChatGPT’s web search mode. It is model-agnostic and MCP-native via JSON-RPC 2.0. (per Bing Search Blog, June 2, 2026)
Why Microsoft Built a Search Engine for AI Agents
Bing was built around human behavior signals — clicks, dwell time, bounce rates. A result ranked well if human users found it useful. That model breaks completely when the “user” is an AI agent executing a multi-step reasoning chain under a tight latency budget.
When developers try to connect AI agents to the live web using standard search APIs, three problems compound immediately. First, traditional APIs return ranked document links — the agent then has to fetch each page, parse HTML, strip navigation and scripts, and extract the relevant passage. Every step adds latency and token consumption. Second, the ranking model optimized for human browsing doesn’t optimize for what an agent needs: completeness, freshness, and authority of the specific passage, not the document overall. Third, at multi-step agentic scale — where an agent may retrieve web information dozens of times per task — the cost of each retrieval call compounds into an expensive, slow pipeline.
Microsoft’s framing, from the official Bing Search Blog announcement by Knut Risvik, Distinguished Engineer for Search and AI: “Latency here is not just user-visible but structurally significant: determining whether a system can afford to take multiple reasoning steps or must compress everything into a single attempt.”
The HTML Parsing Tax
When an agent processes raw HTML from a standard search endpoint, most of its token budget goes to structural tags, navigation menus, scripts, and ads — not the actual factual content it needs. At agentic scale, this destroys both cost efficiency and response quality.
Web IQ’s answer is to move the parsing, extraction, and ranking work to the server side, inside a retrieval stack rebuilt specifically for inference-time grounding — and return only the information the agent actually needs.
Architecture: How Web IQ Was Re-Built from the Ground Up
Web IQ is not Bing with a different API wrapper. Microsoft rebuilt the retrieval stack across every layer — indexing, retrieval, ranking, passage selection, and orchestration — specifically around the demands of agentic workloads.
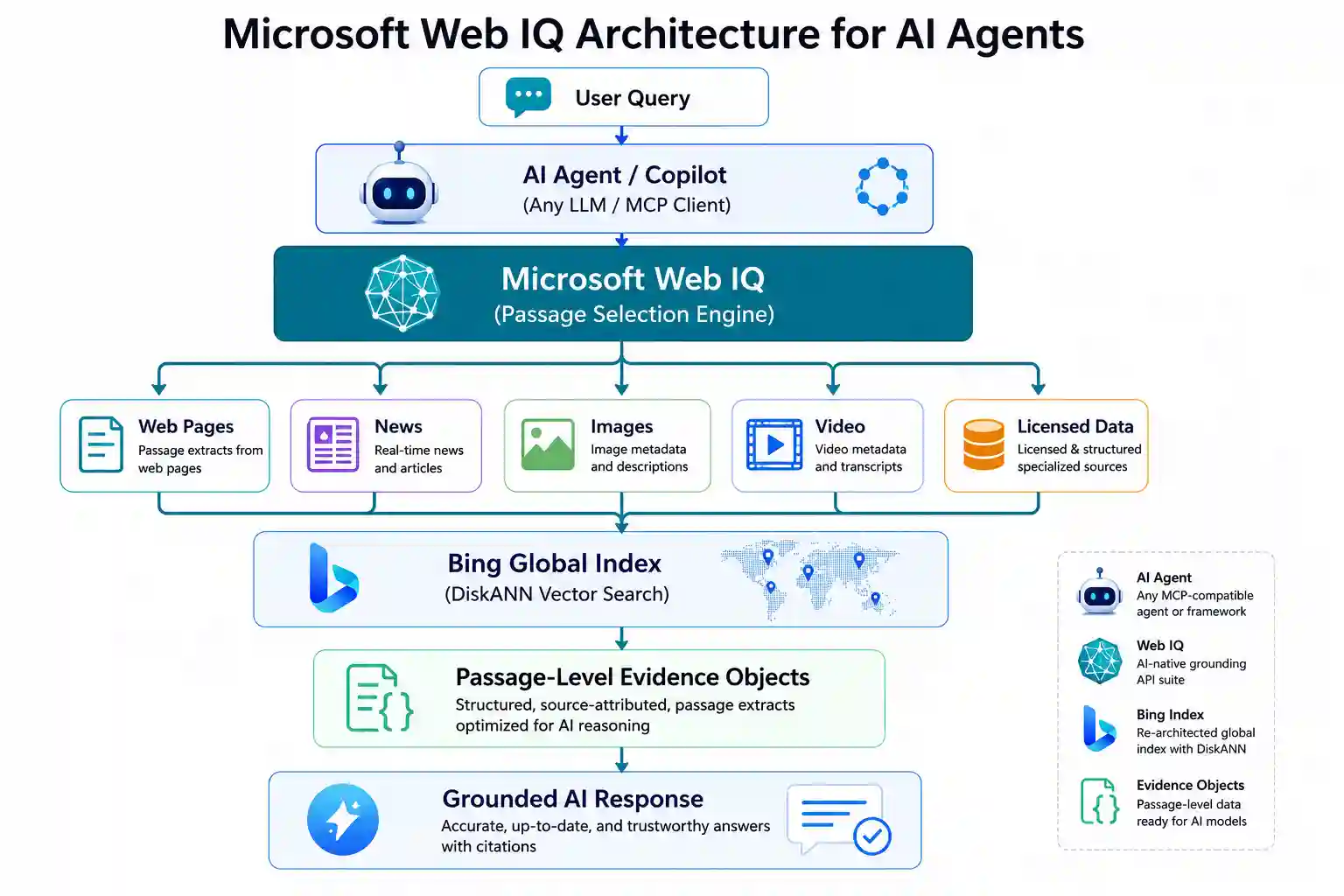
Passage-Level Evidence — Not Document Links
The fundamental output change: Web IQ returns discrete passage extracts rather than document URLs. Each passage is selected for its information density relative to the query — not the document’s overall relevance. An agent receives structured evidence objects it can map directly into its reasoning context without any additional parsing step.
As Microsoft summarizes on the product page: “Models do not need documents, they need the right evidence.”
DiskANN-Based Vector Search
Web IQ’s retrieval layer uses DiskANN — Microsoft’s open-source approximate nearest-neighbor indexing system — extended from their embedding model research. DiskANN enables fast, scalable vector search across Bing’s global-scale index, making passage-level retrieval tractable at query volumes that would be prohibitive with brute-force approaches.
Full-Spectrum Content Coverage
Web IQ covers six content verticals, not just web pages and news. The API surfaces evidence from: web pages, news, images, video, licensed sources, and structured specialized data sources. This is distinct from SERP scraping — Web IQ combines the open web with licensed and specialized sources to deliver authoritative grounding for high-stakes use cases.
Web Pages
Passage-level extracts from Bing’s crawled web index. Selected by information density, freshness, and authority — not traditional document ranking.
News
Real-time news indexing with recency-weighted ranking. Agents get current event grounding without stale cached results.
Images & Video
Visual content metadata and descriptions as structured evidence. Useful for agents that need to reference or validate visual information.
Licensed & Structured Sources
Specialized data sources beyond the open web — including licensed content — for high-stakes domains where open web coverage alone is insufficient.
MCP-Native via JSON-RPC 2.0
Web IQ implements the Model Context Protocol (MCP) via JSON-RPC 2.0. This means any MCP-compatible agent framework can integrate Web IQ without custom adapters or inference lock-in. Developers using frameworks like LangChain, Semantic Kernel, or AutoGen can connect directly to Web IQ through standard MCP tooling.
The MCP-native design is the practical answer to “model-agnostic.” You’re not required to use Azure OpenAI or any Microsoft inference endpoint. Web IQ retrieves the evidence — your agent, running any model, on any infrastructure, receives it. The retrieval and the inference are cleanly separated.
Performance: 164ms P95 Latency Across Five Data Centers
Microsoft benchmarked Web IQ latency across five Azure data center regions: West US2, North Central US, East US2, North Europe, and South Korea. The benchmark used unique queries per test to avoid cache hits, at a configuration of 10 results with 10,000 characters per result. P95 numbers are averaged across data centers.
For context on why 164ms matters structurally: competing grounding API services benchmarked by Microsoft in the same configuration ranged from 406ms to 2,090ms P95 latency. At those speeds, a multi-step agent chain making five retrieval calls would spend 2–10 seconds just on web retrieval before any inference work happens. At 164ms, five calls take under a second.
| Metric | Web IQ | What It Means for Agents |
|---|---|---|
| P95 Latency | 164ms across 5 DCs | Multi-step reasoning chains stay under budget. Each hop costs less than 165ms on the retrieval side. |
| Speed vs Competitors | ~2.5× faster than next-best | Competing services ranged from 406ms–2,090ms P95 in the same configuration. |
| Token efficiency | Pareto-optimal curve | Higher quality with fewer tokens as result count scales from 10 to 20 results. Tested at 3K, 5K, 10K, 20K chars per result. |
| Content volume tested | 10 results, 10K chars/result | Benchmark configuration. Supports configurations from 3K to 20K chars per result. |
| Cache hit avoidance | Unique queries per test | Latency numbers reflect cold-path performance, not cached responses. |
Token Efficiency — “Fewer Tokens In, Better Answers Out, Lower Cost Per Call”
Microsoft’s summary of Web IQ’s efficiency position. Token efficiency was tested across configurations spanning 10, 15, and 20 web results at character limits of 3,000, 5,000, 10,000, and 20,000 per result. Web IQ maintains quality-versus-token count on a favorable Pareto frontier — meaning as you increase result volume, you get more grounding quality without a proportional increase in token cost.
GDSAT — Grounding Satisfaction Quality Metric
Traditional search relevance measures whether a document ranks for a query. GDSAT (Grounding Satisfaction) measures something different: whether the retrieved evidence actually enables accurate downstream reasoning.
Microsoft introduced GDSAT as a first-party quality benchmark covering three dimensions:
Completeness
Does the evidence cover the full scope of what the agent needs to answer the question? Partial evidence that misses key facts degrades reasoning quality even if each passage is individually accurate.
Freshness
Is the content current? Staleness is a critical failure mode for agentic grounding — an agent citing six-month-old data as current produces confidently wrong answers.
Authority
Is the source trustworthy for this query type? A passage from a primary source carries different evidential weight than a summary on an aggregator site.
Microsoft evaluated Web IQ against GDSAT across 3,000 global production queries sampled blind from production traffic, configured at 10 results with 10,000 characters per result. Web IQ reported higher GDSAT scores than competing grounding services in comparable configurations.
What GDSAT Means for Publishers
When Web IQ selects a passage rather than a document, it is making an inclusion decision at the passage granularity — not the page level. Content that scores well on completeness, freshness, and authority will be included. Content that fails on any of these three dimensions may be excluded regardless of its traditional search ranking. Each section of a page needs to be self-contained and extractable to surface in Web IQ responses.
Web IQ also validates results against DeepSearchQA and freshness benchmarks, per the official product page. These are separate from GDSAT and provide additional quality signals for benchmark comparison against competing grounding services.
The Microsoft IQ Stack — Web IQ, Work IQ, and Fabric IQ
Web IQ is one layer in a broader intelligence architecture Microsoft announced at Build 2026. Each layer addresses a distinct data domain. Developers building multi-agent systems need all three, routing queries to the correct layer based on where the relevant information lives.
Web IQ
Open internet grounding. Live web pages, news, images, video, and licensed sources via Bing’s re-architected index. Use for queries about current events, public information, and anything outside the organization’s own data.
Work IQ
Unstructured organizational communication. Microsoft 365 content — emails, Teams messages, SharePoint documents. Use for queries about internal decisions, project history, and organizational knowledge.
Fabric IQ
Structured enterprise data. SQL databases, data warehouses, and OneLake in Microsoft Fabric. Use for queries requiring aggregation, metrics, and analytical results from structured data pipelines.
The practical use case combining all three: an agent verifying an internal corporate strategy (Work IQ) against current public market conditions (Web IQ) before writing a structured summary using the organization’s own financial data (Fabric IQ) — all in one multi-step reasoning chain without leaving the Microsoft ecosystem.
For the Fabric IQ side of this stack, see our Fabric IQ complete guide.
Enterprise Deployment — Azure VNet, Compliance, and Publisher Controls
Azure-Native Infrastructure
Web IQ is hosted within Azure, which means enterprise deployments get the same compliance infrastructure as any other Azure data pipeline: VNet deployment, private endpoints, Azure Monitor logging, and role-based access control. Teams in regulated industries can treat web grounding with the same compliance rigor as internal data access — not as an external black box.
Stateful Retrieval for Multi-Turn Agents
Web IQ supports stateful retrieval — when an agent asks a follow-up question, the API can use the previous grounding context to refine the search without re-sending redundant information. This reduces token consumption across multi-turn conversations and improves coherence in extended agentic workflows.
Robots.txt Compliance and Publisher Controls
Web IQ inherits Bing’s existing robots exclusion protocol compliance and publisher preferences. No new crawler user-agent is introduced — current BingBot configurations govern what Web IQ can access. Website owners manage their content access through the same mechanisms already used with Bing.
Microsoft is also engaging with standards bodies including the IETF on interoperable frameworks for publisher rights in the AI era — a signal that they expect this compliance area to become more formally standardized.
These Are Vendor-Published Benchmarks
All latency, GDSAT, and token efficiency figures are from Microsoft’s internal comparisons as published on the Bing Search Blog and the official Web IQ product page. Microsoft did not publicly name which competing products were used for comparison. Independent third-party benchmarks are not yet available as of June 2026. Evaluate these numbers accordingly before production architecture decisions.
Web IQ vs Competing Grounding Services
Web IQ enters a market where several companies are racing to build the best web grounding infrastructure for AI systems. The key competitors as of June 2026:
| Service | Approach | Key Difference vs Web IQ |
|---|---|---|
| Google Vertex AI (Grounding with Google Search) | Connects models to Google’s search index via the Vertex AI platform | Tied to Google’s model ecosystem. Passage-level vs document-level extraction parity unclear. Not MCP-native. |
| OpenAI Web Browsing (ChatGPT API) | Browser-based tool that fetches and reads pages at query time | Higher latency from live page fetch. Not a dedicated grounding API — more of a tool use pattern than a retrieval service. |
| Perplexity API | Search-grounded AI with passage extraction | Consumer-focused search product. Less enterprise compliance infrastructure. Not Azure-native. |
| Brave Search API | Independent search index with AI grounding endpoint | Smaller index than Bing. No Microsoft enterprise compliance integration. |
| Firecrawl / Jina AI | Live web crawl and extraction at query time | Real-time crawl vs pre-indexed — higher freshness ceiling but much higher latency. Different use case: specific URL extraction vs query-based retrieval. |
Web IQ’s structural advantage is the combination of Bing’s existing global-scale index (two decades of crawl infrastructure), a retrieval stack rebuilt specifically for agentic workloads, Azure enterprise compliance infrastructure, and MCP-native integration — none of which any single competitor offers as a combined package at launch.
The gap that remains: pricing and general availability. As of June 11, 2026, Web IQ is limited access via waitlist only. Until pricing is published, total cost of ownership comparisons against Grounding with Bing Search (the existing Microsoft product it supersedes) and competitor services are not possible.
How to Get Access to Microsoft Web IQ
Web IQ launched in limited access at Microsoft Build 2026 on June 2, 2026. It is currently available through a waitlist.
- Waitlist registration: webiq.microsoft.ai — express interest for early access
- Existing Grounding with Bing Search customers: Continue to have access to the existing service. Web IQ is a separate, more capable successor product — not a forced migration
- Pricing: Not announced as of June 11, 2026
- General availability timeline: Not announced
- Launch partner — Replit: Replit is an early integration partner for the developer experience. Replit users building AI apps can connect to Web IQ as part of the agentic backend workflow
- MCP tooling: Integration available to any MCP-compatible framework via JSON-RPC 2.0 — no Microsoft inference endpoint required
What “Grounding with Bing Search” Customers Should Know
Microsoft confirmed existing Grounding with Bing Search customers are not cut off. The two services run in parallel. Web IQ is not a deprecation notice for Grounding with Bing Search — it is a new, separate product with a different architecture and access model. No migration deadline has been set.
Frequently Asked Questions
Official References & Related Guides
⚠️ Accuracy Disclaimer
All performance figures — 164ms P95 latency, 2.5× speed advantage, GDSAT scores, and token efficiency claims — are sourced from Microsoft’s internal benchmarks as published on the official Bing Search Blog announcement and the Web IQ product page. Microsoft did not publicly identify which competing products were used for comparison benchmarks. Independent third-party evaluations are not yet available as of June 2026. Web IQ is currently in limited access — pricing, API documentation, and GA timeline are not published. Verify current status at webiq.microsoft.ai before architecture decisions. UIG Data Lab is an independent publication, not affiliated with or endorsed by Microsoft Corporation.